منظور از داده کاوی ( Data Mining ) چیست ؟
داده کاوی فرآیند استخراج و کشف الگوها در مجموعه داده های بزرگ است که شامل روش هایی در رویارویی یادگیری ماشین ، آمار و سیستم های پایگاه داده می باشد . داده کاوی یک زیرشاخه میان رشته ای از علوم کامپیوتر و آمار با هدف کلی استخراج اطلاعات (با روش های هوشمند) از مجموعه داده ها و تبدیل اطلاعات به ساختاری قابل درک برای استفاده بیشتر است. بعبارت دیگر داده کاوی مرحله تجزیه و تحلیل کشف دانش در پایگاه های داده یا KDD است. (knowledge discovery in databases)
باید توجه داشت "داده کاوی" در واقع یک اصطلاح جامع نیست زیرا هدف استخراج الگوها و دانش از مقادیر زیادی داده است، نه فقط استخراج ( کاوی ) خود داده ها . همچنین داده کاوی یک کلمه کلیدی است و اغلب برای هر شکلی از داده ها یا پردازش اطلاعات در مقیاس بزرگ ( جمع آوری ، استخراج ، انبارداری ، تجزیه و تحلیل و آمار) و همچنین هر کاربرد سیستم پشتیبانی تصمیم گیری رایانه ای ، استفاده می شود. اصطلاح داده کاوی فقط به دلایل بازاریابی مرسوم شده است .
وظیفه واقعی داده کاوی تجزیه و تحلیل نیمه خودکار یا خودکار مقادیر زیادی از داده ها برای استخراج الگوهای ناشناخته قبلی است مانند گروه رکوردهای داده ها ( تحلیل خوشه ای )، رکوردهای غیرمعمول ( تشخیص ناهنجاری ) و وابستگی ها (مانند استخراج الگوی متوالی). این الگوها سپس میتوانند بهعنوان خلاصهای از دادههای ورودی دیده شوند، و ممکن است در تجزیه و تحلیل بیشتر یا برای مثال: در یادگیری ماشین و تجزیه و تحلیل پیشبینیکننده استفاده شوند.
مرحله داده کاوی ممکن است چندین گروه را در داده ها شناسایی کند، که بعدا بتواند برای به دست آوردن نتایج پیش بینی دقیق تر توسط یک سیستم پشتیبانی تصمیم مورد استفاده قرار دهد . مراحل جمعآوری دادهها، آمادهسازی دادهها، و تفسیر نتایج و گزارشدهی بخشی از مراحل دادهکاوی نیستند و بهعنوان مراحل اضافی به فرآیند کلی KDD تعلق دارند.
تفاوت بین تجزیه و تحلیل داده و داده کاوی در این است که تجزیه و تحلیل داده ها برای آزمایش مدل ها و فرضیه ها در مجموعه داده ها استفاده می شود، مانند اثربخشی یک کمپین بازاریابی ، صرف نظر از میزان داده ها.
در مقابل، داده کاوی از یادگیری ماشینی و مدل های آماری برای کشف الگوهای مخفی یا پنهان در حجم زیادی از داده ها استفاده می کند.
واژههای مرتبط لایروبی داده ، ماهیگیری داده ، و جاسوسی داده (data dredging , data fishing , and data snooping ) به استفاده از روشهای داده کاوی برای نمونهبرداری از بخشهایی از مجموعه دادههای جمعیتی بزرگتر اشاره دارد که برای استنباط آماری قابل اعتماد در مورد اعتبار هر یک از آنها بسیار کوچک باشند این روشها میتوانند در ایجاد فرضیههای جدید برای آزمایش در برابر جمعیتهای داده بزرگتر استفاده شوند.
اصطلاح داده کاوی در حدود سال 1990 در جامعه پایگاه داده ظاهر شد، سایر اصطلاحات استفاده شده عبارتند از: جمع آوری اطلاعات ، کشف اطلاعات ، استخراج دانش ، و غیره ...... در حال حاضر، اصطلاحات داده کاوی و کشف دانش به جای یکدیگر استفاده می شوند.
استخراج دستی الگوها از داده ها برای قرن ها اتفاق افتاده است. روش های اولیه شناسایی الگوها در داده ها شامل قضیه بیز و تحلیل رگرسیون است. تکثیر، فراگیر شدن و افزایش قدرت فناوری رایانه به طور چشمگیری توانایی جمع آوری، ذخیره سازی و دستکاری داده ها را افزایش داده است. با افزایش اندازه و پیچیدگی مجموعه داده ها ، تجزیه و تحلیل مستقیم داده ها به طور فزاینده ای با پردازش غیرمستقیم و خودکار داده ها، به کمک سایر اکتشافات در علوم کامپیوتر، به ویژه در زمینه یادگیری ماشین، مانند شبکه های عصبی، تقویت شده است .
تجزیه و تحلیل خوشه ای ، الگوریتم های ژنتیک(دهه 1950)، درختان تصمیم و قوانین تصمیم (دهه 1960)، و ماشین های بردار پشتیبان (دهه 1990) که در داده کاوی فرآیند بکارگیری این روش ها با هدف کشف الگوهای پنهان است.
فرآیند کشف دانش در پایگاه های داده (KDD) معمولاً با مراحل زیر تعریف می شود:
انتخاب
پیش پردازش
دگرگونی
داده کاوی
تفسیر/ارزیابی
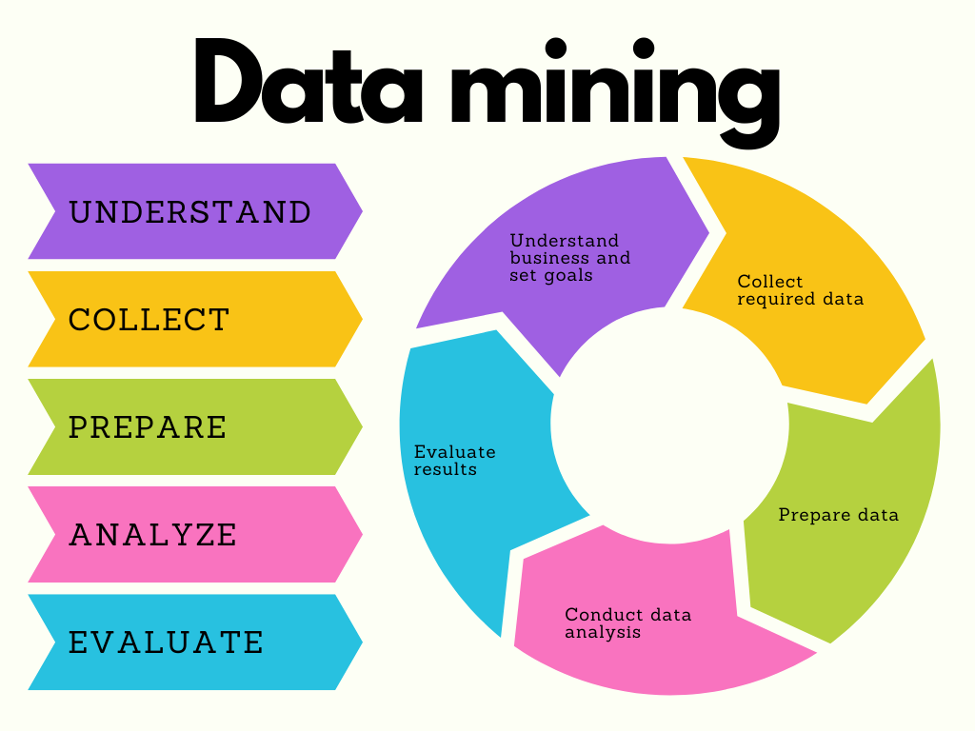
فرآیند استاندارد سازی در صنعت برای داده کاوی شش مرحله را تعریف می کند:
درک کسب و کار
درک داده ها
آماده سازی داده ها
مدل سازی
ارزیابی
گسترش
قبل از اینکه بتوان از الگوریتم های داده کاوی استفاده کرد، یک مجموعه داده هدف باید مونتاژ شود. از آنجایی که دادهکاوی فقط میتواند الگوهای موجود در دادهها را آشکار کند، مجموعه دادههای هدف باید به اندازهای بزرگ باشد که حاوی این الگوها باشد و در عین حال به اندازه کافی مختصر باشد تا در یک محدودیت زمانی قابل قبول استخراج شود. یک منبع متداول برای داده ها، دیتا مارت یا انبار داده (data mart or data warehouse ) است . پیش پردازش برای تجزیه و تحلیل مجموعه داده های چند متغیره قبل از داده کاوی ضروری است. سپس مجموعه هدف تمیز می شود. پاکسازی داده ها مشاهدات حاوی نویز و مشاهدات با داده های از دست رفته را حذف می کند .
داده کاوی شامل شش کلاس رایج از وظایف است:
تشخیص ناهنجاری - شناسایی رکوردهای داده غیرعادی، که ممکن است جالب باشد یا خطاهای داده ای که نیاز به بررسی بیشتر دارد.
مدل سازی وابستگی - روابط بین متغیرها را جستجو می کند. به عنوان مثال، یک سوپرمارکت ممکن است داده هایی را در مورد عادات خرید مشتری جمع آوری کند. با استفاده از یادگیری قوانین تداعی، سوپرمارکت می تواند تعیین کند که کدام محصولات اغلب با هم خریداری می شوند و از این اطلاعات برای اهداف بازاریابی استفاده کنند. گاهی اوقات به آن تحلیل سبد بازار نیز گفته می شود.
خوشهبندی – وظیفه کشف گروهها و ساختارهایی در دادهها است که به نوعی «مشابه» هستند، بدون استفاده از ساختارهای شناخته شده در دادهها.
طبقه بندی - وظیفه تعمیم ساختار شناخته شده برای اعمال به داده های جدید است. به عنوان مثال، یک برنامه ایمیل ممکن است سعی کند یک ایمیل را به عنوان "مشروع" یا "هرزنامه" طبقه بندی کند.
رگرسیون - تلاش برای یافتن تابعی که داده ها را با کمترین خطا مدل سازی می کند تا روابط بین داده ها یا مجموعه داده ها را تخمین بزند.
خلاصه سازی - ارائه یک نمایش فشرده تر از مجموعه داده ها، از جمله تجسم و تولید گزارش.
دادهکاوی میتواند ناخواسته مورد سوء استفاده قرار گیرد و نتایجی ایجاد کند که به نظر میرسد مهم هستند اما در واقع رفتار آینده را پیشبینی نمیکنند و نمیتوانند در نمونه جدیدی از دادهها بازتولید شوند، بنابراین کاربرد کمی دارند. این امر گاهی به دلیل بررسی بیش از حد فرضیه ها و انجام ندادن آزمون فرضیه های آماری مناسب ایجاد می شود . یک نسخه ساده از این مشکل در یادگیری ماشین به نام بیشبرازش شناخته میشود ، اما همان مشکل میتواند در مراحل مختلف فرآیند ایجاد شود و بنابراین یک تقسیم قطار/آزمایش - در صورت امکان - ممکن است برای جلوگیری از این اتفاق کافی نباشد.
مرحله نهایی کشف دانش از داده ها، تأیید این است که الگوهای تولید شده توسط الگوریتم های داده کاوی در مجموعه داده های گسترده تر رخ می دهند. همه الگوهای یافت شده توسط الگوریتم ها لزوما معتبر نیستند. معمولا الگوریتم های داده کاوی الگوهایی را در مجموعه آموزشی پیدا می کنند که در مجموعه داده های عمومی وجود ندارد. که به آن overfitting گفته می شود و معمولا ارزیابی از مجموعه آزمونی از داده ها استفاده می کند که الگوریتم داده کاوی بر روی آن آموزش داده نشده است. الگوهای آموخته شده در این مجموعه تست اعمال می شود و خروجی حاصل با خروجی مورد نظر مقایسه می شود. به عنوان مثال، یک الگوریتم داده کاوی که سعی می کند "هرزنامه" را از ایمیل های "مشروع" تشخیص دهد،
در صورتی که الگوهای آموخته شده مطابق با استانداردهای مورد نظر نباشد، لازم است مراحل پیش پردازش و داده کاوی مجدد مورد ارزیابی و تغییر قرار گیرد. اگر الگوهای آموخته شده استانداردهای مورد نظر را برآورده کنند، در مرحله آخر باید الگوهای آموخته شده را تفسیر کرد و آنها را به دانش تبدیل کرد.
برای تبادل مدلهای استخراجشده بویژه برای استفاده در تحلیلهای پیشبینیکننده - استاندارد کلیدی زبان نشانهگذاری مدل پیشبینیکننده است که یک زبان مبتنی بر XML است که توسط گروه دادهکاوی (DMG) توسعه یافته و به عنوان فرمت تبادل توسط بسیاری پشتیبانی میشود. برنامه های کاربردی داده کاوی همانطور که از نام آن پیداست، فقط مدلهای پیشبینی را پوشش میدهد، یک وظیفه داده کاوی خاص که برای برنامههای تجاری اهمیت بالایی دارد. با این حال، برنامه های افزودنی برای پوشش (به عنوان مثال) خوشه بندی زیرفضا مستقل از DMG پیشنهاد شده است.
کاربردهای قابل توجه
داده کاوی امروزه در هر جایی که داده های دیجیتالی در مقیاس بزرگ موجود است استفاده می شود. نمونه های قابل توجهی از داده کاوی را می توان در سراسر تجارت، پزشکی، علم و فناوری و نظارت یافت.
نگرانی های حریم خصوصی و اخلاق
در حالی که اصطلاح "داده کاوی" خود ممکن است هیچ پیامد اخلاقی نداشته باشد، اغلب با استخراج اطلاعات در رابطه با رفتار کاربر (اخلاقی و غیره) همراه است.
داده کاوی به آماده سازی داده نیاز دارد که اطلاعات یا الگوهایی را آشکار می کند که محرمانگی و تعهدات حریم خصوصی را به خطر می اندازد . یک راه متداول برای این اتفاق از طریق تجمیع داده ها است . تجمیع دادهها شامل ترکیب دادهها با هم (احتمالاً از منابع مختلف) بهگونهای است که تجزیه و تحلیل را تسهیل میکند (اما همچنین ممکن است شناسایی دادههای خصوصی، سطح فردی را قابل استنتاج یا آشکار کند). این به خودی خود داده کاوی نیست، اما نتیجه آماده سازی داده ها قبل از تجزیه و تحلیل و برای اهداف آن است. تهدید حریم خصوصی افراد زمانی مطرح میشود که دادهها پس از جمعآوری، باعث میشوند که دادهکاوی یا هر کسی که به مجموعه دادههای تازه جمعآوریشده دسترسی دارد، بتواند افراد خاصی را شناسایی کند، بهخصوص زمانی که دادهها در ابتدا ناشناس بودند.
خلاصه ای از مقاله ویکی پدیا : https://en.wikipedia.org/wiki/Data_mining
نکته مهم در پیاده سازی عملی داده کاوی اینست که به دلیل حجم فوق العاده بالای داده در امر ذخیره و بازیابی نمی توان از بانک های اطلاعاتی عادی مانند SQL یا Oracle استفاده نمود و بستر پایگاه دادهای بسیار بزرگ بر روی پلت فرم های دیگری بنیان گذاشته می شوند که در مقاله زیر یکی از آنها مورد بررسی قرار گرفته است :
آشنایی با هدوپ .........










